Hello,
I have a very strange connection issue, trying to proxy redis servers.
First, the relevant configuration extract:
defaults
mode http
log global
option httplog
option dontlognull
option dontlog-normal
option http-ignore-probes
timeout connect 5000
timeout client 50000
timeout server 50000
maxconn 25000
frontend redis
bind *:6362
mode tcp
use_backend redis
timeout client 3h
option srvtcpka
backend redis
mode tcp
timeout server 3h
option clitcpka
server cache01 cache01:6381 check
Under heavy load, connections are randomly dropped, but limits are not hit when I check haproxy stats (~50 open connections).
(To add extra details, it’s a celery ‘client’ instance, using redis as a result backend, failing to submit new tasks).
HaProxy logs show this:
Jan 28 11:40:30 localhost haproxy[17014]: 127.0.0.1:37852 [28/Jan/2019:11:08:59.155] redis redis/cache01 1/0/1891613 2421222 SD 133/98/97/97/0 0/0
Jan 28 11:40:41 localhost haproxy[17014]: 127.0.0.1:43558 [28/Jan/2019:11:40:30.805] redis redis/cache01 1/0/10482 2605056 CD 133/98/97/97/0 0/0
Extra remark: it seems the double disconnect always together.
Extra details: the client application receive a socket.timeout (Python).
There is no issues with a direct connection: this only happens with HaProxy in between (but we need it ^^).
The issue happens on different system / linux kernls: We can reproduce it locally on a single “basic” archlonux machine or in debian stable containers on a “powerfull” server.
Having no idea who was responsible (Celery ↔ Ha or Ha ↔ Redis), we started to dump networks packets:
For the first connection (37852, closed at 11:40:30), we have the following timeline:
11.08.59 celery → ha Connection opened. ha → redis opened a few milliseconds later
11:09:00 ha → celery: At tcp level, the window seem to be full (On celery side)
11:09:00 celery → ha: Celery is starting to send tcp packets with a window of zero
11:09:10 After a few keep-alive from ha to celery, celery start again to send data, but window is still set to 0. No data traffic from ha to celery anymore in the full dump.11:11:05 redis → ha: At tcp level, window seems to be full (On haproxy side)
11:11:05 ha → redis: HaProxy is starting to send tcp packets with a window of zero
11:11:11 After a few keep-alive, haproxy start again to send data, but window is still set to 0. No data traffic form redis to celery will be seen again.11:21:17 redis → ha: At tcp level, window seems to be full (On redis side)
11:21:17 redis start to send tcp packets with a window of zero as well
11:22:35 redis close the connection11:36:45: ha → redis: At tcp level, window seems to be full (On haproxy side). At thing point no more traffic is exchanged
11:38:50 Last tcp ack
11:40:30: Celery closed the connection
Remark 1: There is data “lost” in HaProxy buffer: the traffic redis → ha → celery is not send anymore at 11:09:00, and redis → ha is stopped at 11:11:05 (so there is ~2 minutes of traffic in haproxy buffers).
Remark 2: Why redis didn’t closed the front connection when the back connection was lost ? I’m 99% sure that I see the two connections in tcp dump (correct timing, same data when everything was working)
For the second connection, the issue is quite similar:
Timeline:
11:40:30: Connection opened
11:40:33: Last message from HA to celery (window full), but no pause in data from celery to ha
11.40:41: Celery close the connection
11:40:41: Ha close the connection to redis
This second case make more sense (no pause in data flow, front is closed to back is closed immediately).
Some screenshot of tcpdumps in case I missed something:
Case 1:
SYNs


Celery full

Backend Haproxy full

Redis full and clsoe
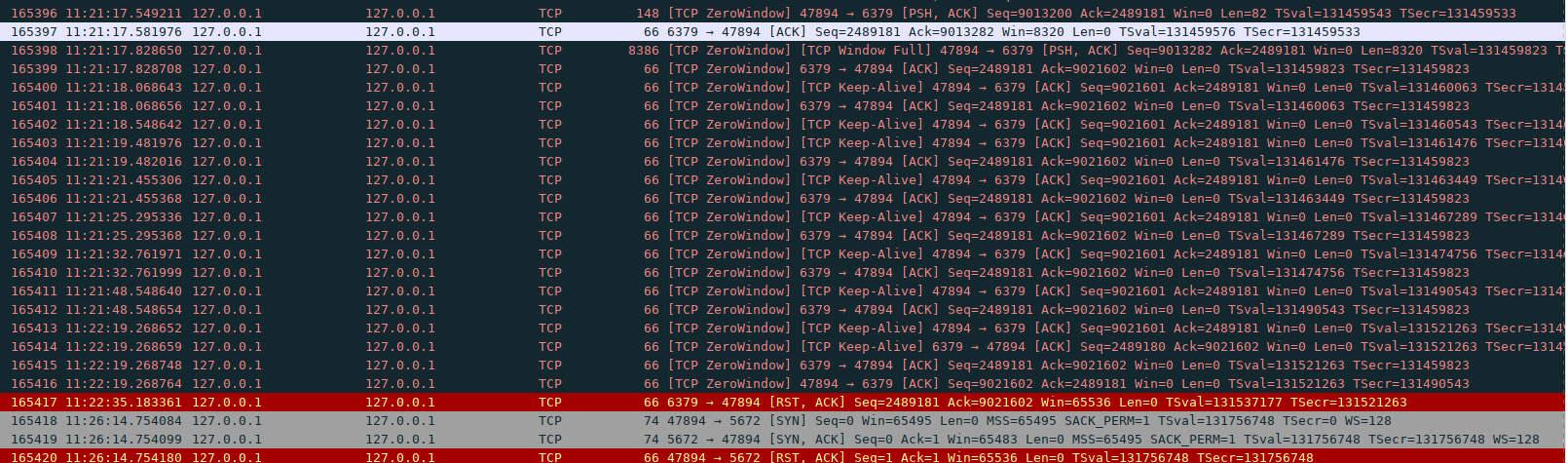
Frontend Haproxy full and clsoe

Case 2:
SYNs


Celery full

Celery close

Redis close

I don’t understand why this is happening only with haproxy in between. There is load on the system, but it’s seems unlikely that the celery client is unable to find time to consume his buffer for ~30 minutes, especially when he find time to send data.
This cloud be a client (redis-py is used by celery) issue, but I was wondering if it could be a haproxy configuration issue and/or someone have any hits to try to fix the issue.
Thanks for your help!